Receipt hell
March, 2024 · 5 min read
With the way things are, accounting solutions all have a blind spot. While many of them can parse PDF receipts and invoices, a prerequisite is that you’ve already gotten hold of those documents. In other words, these solutions cannot alleviate the painstaking process of collecting and organizing them, even if we’re only talking about digital receipts.
This manual process is painful because there aren’t any standards or sufficient legal requirements. Ideally, you’d want each service to deliver receipts to a single place of your choosing at the instant of payment. In reality, and typical for Swedish services, they force you to log in to go looking for them. Because there aren’t any standards, it’s simply not feasible for accounting solutions to generically solve this user experience.
Here are all the challenges and how I tackled some of them through a Chrome plugin. While invoices and receipts are different – for the sake of simplicity, we’ll refer to them both as receipts from here on out.
Inconsistent user experience
We’re all used to the experience of going to a store, buying something, and then receiving a receipt after payment. For the most part, the experience is similar for digital services and even for subscriptions like Google Workspaces – every month, Google automatically deducts money and sends me a PDF receipt to my email.

However, I’ve found that Swedish companies that sell a subscription, like my bank and my phone provider, typically don’t do this. They’ll happily take my company’s money without taking care of actually delivering a receipt. For each such service, I have to go through their logins. Then, find and download the required receipts.
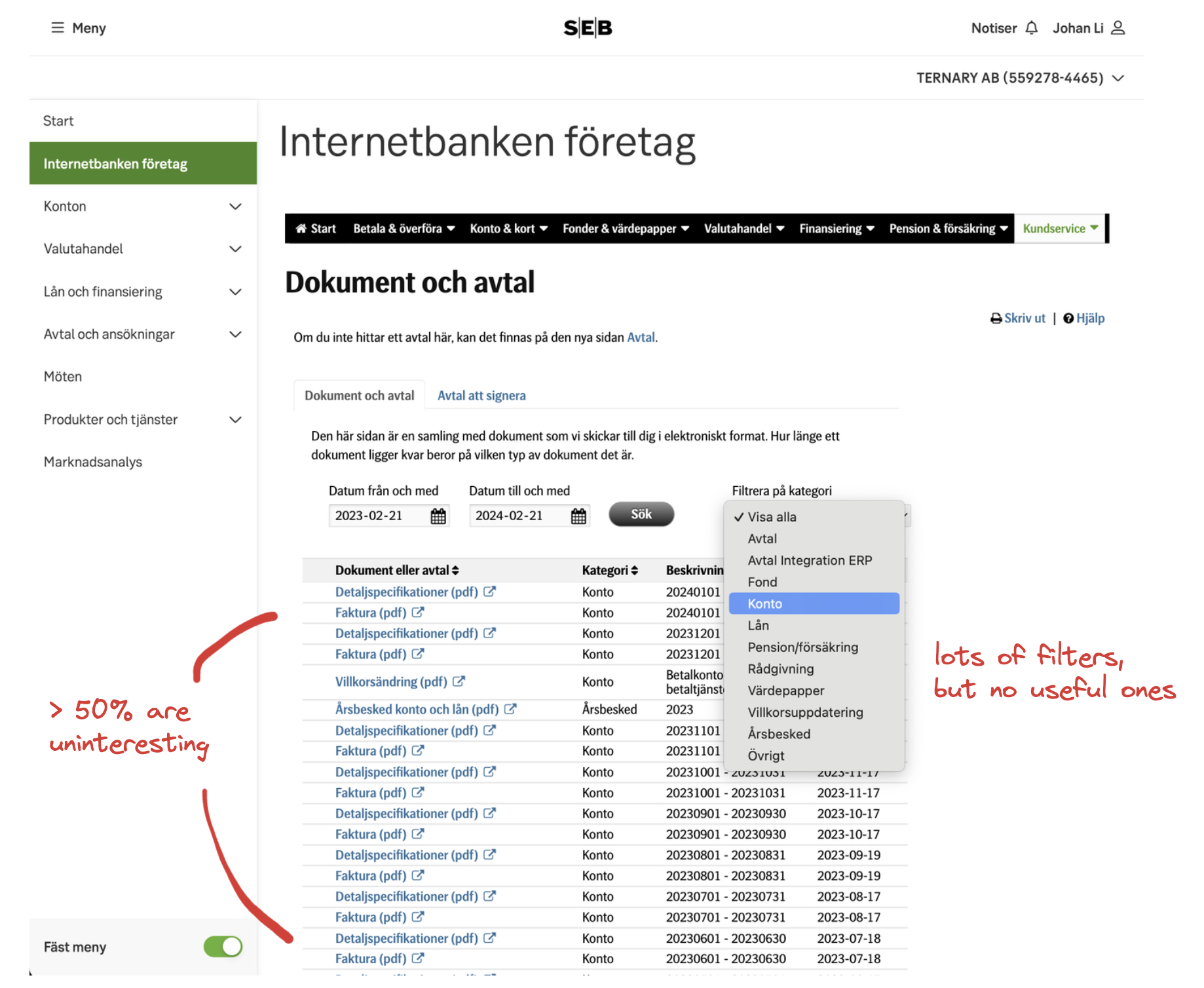
I hope my assets don’t get frozen for saying this, but my bank is the worst offender. Finding their receipts is unintuitive. They mix receipts with other irrelevant files. You can filter a bunch of stuff, yet there’s no way to filter only the receipts. While they’ve improved in this regard, it used to be that all receipts took some time to download because they were always generated on demand and never cached.
Also, you can’t take receiving a receipt for granted. An insurance company, and a major one at that, siphons money from me every month. Yet, they don’t produce any receipts except for the first installment. Their FAQ even tells you verbatim to forge the first receipt by altering the dates. I have no idea how they get away with this – could they spread this practice to all the other Swedish service providers, pretty please? It’d make life so much easier for me.
Nondescript filenames
Filenames matter! Here’s what most of my monthly receipts’ filenames look like:
- VDR,MIRX002P02,20231219064100,MIR3-0000000000000000099663425.pdf
- 4897546884.pdf
- invoice-S19372.pdf
- Faktura_2023-05-18_db5d07b1.pdf
These filenames are far from ideal because every time you go on a receipt-hunting session, you’ll end up with a Downloads folder filled with indiscernible files. As there’s effort involved in obtaining most receipts, it’s more efficient to download multiple months’ receipts in one go, making this problem even worse.
Services should treat filenames like an external label – they’re there for the users’ sake. Preferably, all filenames should be of a format like SERVICE-DATE.pdf, e.g., SEB-2024-02-24.pdf. Then, just glancing at your Downloads folder will tell you a lot more.
One-size-fits-all logins and BankID
As discussed earlier, many Swedish subscription services don’t actively provide you with receipts. There are also two additional annoyances.
The services I use don’t have sophisticated logins and authentication. Let me clarify: if you use something like Gmail, Facebook, or GitHub, your sessions are typically very long-lived. Only if you intend to perform sensitive or high-risk actions, or perhaps when you revisit from new IP addresses, do these services have you re-authenticate. They also let you decide how to authenticate and whether to “remember you”.
I get it – it’s prohibitively expensive to implement systems like that, especially if you can’t even get your login working half the time. But having a login that essentially lumps receipt downloads with the ability to wire all your money to another account is highly inconvenient.

The other annoyance is that Swedish services almost exclusively use BankID. BankID is a strong form of authentication. It’s tied to your national identification number, and you must visit a bank physically to get it issued. You log in by scanning a QR code generated by the service and then entering your fingerprint or PIN.
The issue with BankID, and most likely by design, is that you can’t have your browser save and autofill your credentials like with username and password. BankID also doesn’t function like single sign-on, where one active session lets you log into multiple services without explicitly logging in again. Part of the reason, I suspect, is because older BankID implementations didn’t involve QR codes. You fill in a national identification number, and BankID would be triggered, meaning it’s trivial for bad actors to take advantage of.
Don’t get me wrong – I like BankID. I just don’t want to scan a QR code and enter my fingerprint a half dozen times every time I download receipts from different services. Let me view them by entering an autosaved username and password, and, for the love of God, don’t set five-minute sessions. Better yet, just email them to me.
Tackling these issues
If a service causes lots of bookkeeping overhead, you can always switch to another one. But if these issues seem to be the rule rather than the exception, what can you do about it? Automating BankID logins is out of the question – I don’t want to play around with something that can wipe out my life savings. What’s left is improving the user experience post-login.
Chrome extension
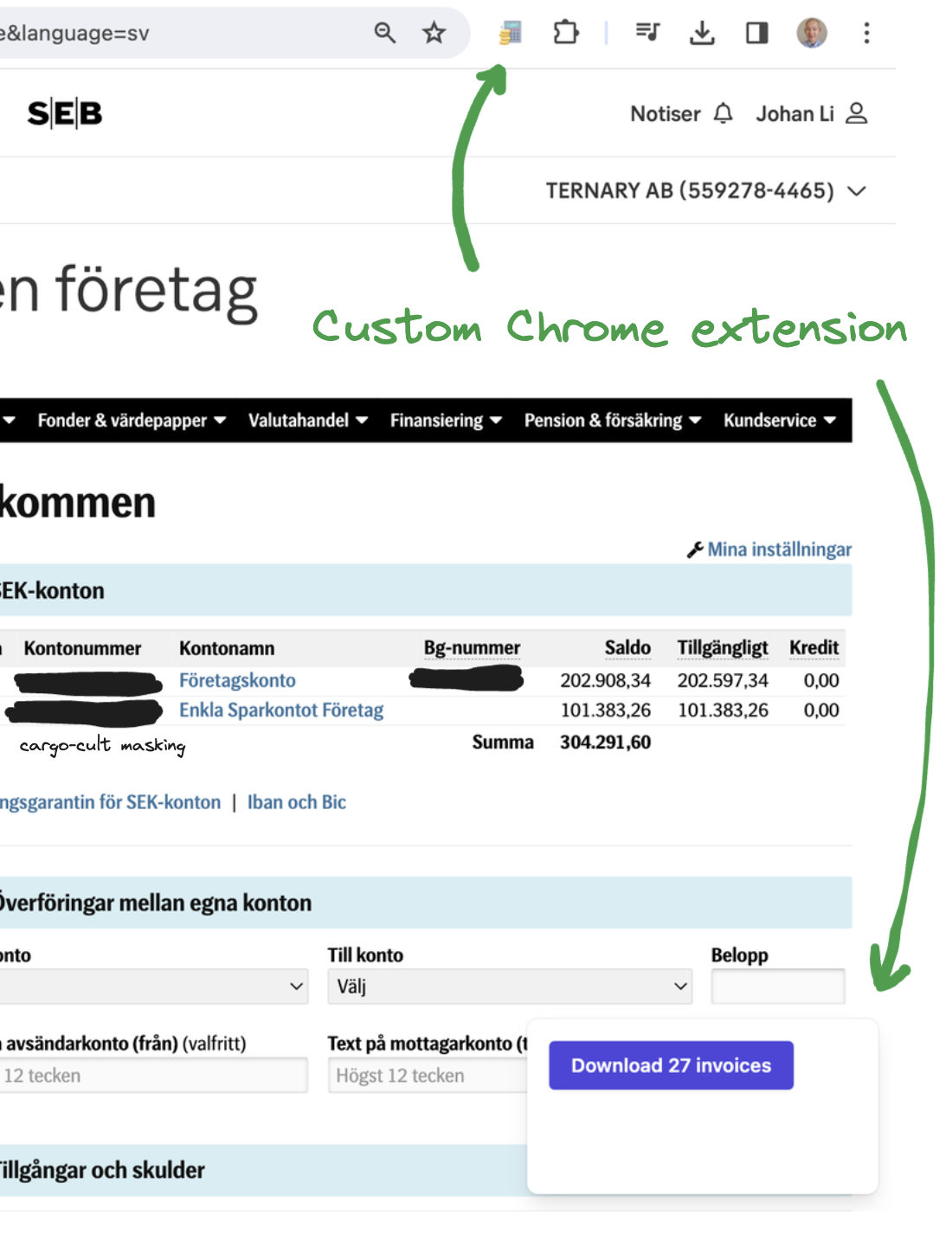
To standardize the experience across services, I created a Chrome extension, where every service has a custom script to determine all the receipt URLs. After logging in, no matter the service, a small dialog containing a “Download X invoices” button will appear.
Initially, I had the extension also figure out what date applied to each file, e.g., by looking at table cells or an API response. After downloading, it would save files to a folder structure like {SERVICE}/{SERVICE}-{DATE}.pdf. But because I had to handcraft scripts for each service, I ditched this. A solution that requires as little non-generic business logic as possible is better.
Document parser
Instead, all files I would’ve otherwise downloaded are sent to an endpoint that parses them. Since I only use a handful of services, and services use the same template for all their receipts, it isn’t too tricky to programmatically recognize SERVICE and DATE from such services.
Also, the Downloads folder disappears. As I’m never going to handle many files, they’re simply stored in a Postgres database for maximum portability.